この記事は 語学・言語学・言語創作 Advent Calendar 2020 の 10 日目です。
人工言語にしろ何にしろ、言語の文法について考えようと思ったとき、チョムスキー階層というのを目にしたことがあるのではないでしょうか。

この中でも正則文法というのは、最も制限の強い文法になっています。
この正則文法によって人工言語的な営みをすることがどの程度可能か? というのが本記事のテーマです。
定義とかの話なので面倒なら飛ばしてください
言語と文法
まず、ここでの言語と文法の定義を書いておきます。
最初に記号というものを定めます。a, b, c, , ., ...みたいな感じです。
言語とは、記号列の集合のことです。上で決めた記号を適当に並べたとき、mi pilin pona, hellooooooo, askldjfahqrweklahfukseh など無限の組み合わせが存在しますが、この中で有効なもののみを集めたものが言語です。もちろん言語自体も無限の大きさの集合になり得ます。
文法とは、ふたつの捉え方がありますが、ひとつはその言語に沿うような記号列を生成するルールのことです。これには後述の正則文法などが該当します。もうひとつは、ある記号列がその言語に含まれるか判定するルールのことです。これには後述の非決定性有限オートマトンなどが該当します。どちらにせよ、その言語を定めるためのルールのことを文法といいます。
正則文法の定義
正則文法は制限が強く、ルールが全て以下のような形になっています。
A -> a BA -> aA -> ε
小文字はその言語で使う記号のどれかです。大文字はそれを置き換えることができるある種の変数のようなものです。ε は空文字のことです。
最初に決まった大文字から始めて、ルールによってどんどん置き換えていくことで記号列を生成していきます。
ちなみに、A -> a B でなく A -> B a を使うものもあり、前者は右線形文法、後者は左線形文法と呼ばれます。
正則言語の等価な定義
正則言語とは、以下を満たす言語のことであり、いずれも等価です。
正則文法と人工言語
さて、文法が簡単な人工言語のひとつとして、トキポナという言語がありますね。
正則文法がどの程度人工言語に対して運用可能か考える上で、トキポナが正則言語であるかどうかを調べれば、トキポナは運用可能な人工言語である(個人の感想)のでお題を満たすということになります。
が、実際にトキポナには公式な形式文法は定められていません(多分)。そもそも、トキポナは話者によって多少ルールが異なる場合があり、あるトキポナ文が非文かどうかは話者によっても異なると思います。
そうするとトキポナが正則言語であることを形式的に証明することは難しいのですが、今回の目的は人工言語一般に対する話なので、「トキポナの文法をよく近似している形式文法」を考えることで、本当のトキポナとの細かい差異を気にせず、人工言語としての運用を考えることができます。
ほぼトキポナ形式文法を用意する
トキポナっぽい形式文法は多分色々考えられているでしょうが、とりあえずググって出てきたこの PDF を使います。
https://www2.hawaii.edu/~chin/661F12/Projects/ztomaszewski.pdf
Appendix の部分にこのようなルールが載っています。
トキポナを正規表現に変換する
これが正則言語かどうかを形式的に証明するには、上で述べた等価な形のどれかに変換する必要があります。
これを正則文法のルールに変換するのはしんどいので、正規表現に変換することを考えてみます。
固有名詞
トキポナの音韻規則として、
- 音節
jiwuwotiは存在しない nで終わる音節の次にmnで始まる音節は続かない
というものがあります。これを考慮したトキポナの単語を表す正規表現としては以前
トキポナ単語用正規表現
— ごちうさで学ぶトキポナbot (@pilinponapona) 2016年3月23日
/^(?!.*(?:ji|wu|wo|ti|nm|nn))[j-npstw]?[aeiou]n?(?:[j-npstw][aeiou]n?)*$/i#tokipona
のようなものを考えたのですが、先読みを使ってしまうと正規表現にならない(?????? これは大抵のプログラミング言語で使われている正規表現が実際には正規表現でないことによります)のでこれを先読みを使わないものに変換します。
存在しない音節については逆に存在する音節を列挙すればいいです。n に関しては、逆に n の前に関して制限がないので、後ろとセットにして列挙すればいいです。
- 語頭:
A|E|I|O|U|Ja|Je|Jo|Ju|Ka|Ke|Ki|Ko|Ku|La|Le|Li|Lo|Lu|Ma|Me|Mi|Mo|Mu|Na|Ne|Ni|No|Nu|Pa|Pe|Pi|Po|Pu|Sa|Se|Si|So|Su|Ta|Te|Ti|To|Tu|Wa|We|Wi nなし後続音節:ja|je|jo|ju|ka|ke|ki|ko|ku|la|le|li|lo|lu|ma|me|mi|mo|mu|na|ne|ni|no|nu|pa|pe|pi|po|pu|sa|se|si|so|su|ta|te|ti|to|tu|wa|we|winあり後続音節:nja|nje|njo|nju|nka|nke|nki|nko|nku|nla|nle|nli|nlo|nlu|npa|npe|npi|npo|npu|nsa|nse|nsi|nso|nsu|nta|nte|nti|nto|ntu|nwa|nwe|nwi
まとめると
(?:A|E|I|O|U|Ja|Je|Jo|Ju|Ka|Ke|Ki|Ko|Ku|La|Le|Li|Lo|Lu|Ma|Me|Mi|Mo|Mu|Na|Ne|Ni|No|Nu|Pa|Pe|Pi|Po|Pu|Sa|Se|Si|So|Su|Ta|Te|Ti|To|Tu|Wa|We|Wi)(?:ja|je|jo|ju|ka|ke|ki|ko|ku|la|le|li|lo|lu|ma|me|mi|mo|mu|na|ne|ni|no|nu|pa|pe|pi|po|pu|sa|se|si|so|su|ta|te|ti|to|tu|wa|we|wi|nja|nje|njo|nju|nka|nke|nki|nko|nku|nla|nle|nli|nlo|nlu|npa|npe|npi|npo|npu|nsa|nse|nsi|nso|nsu|nta|nte|nti|nto|ntu|nwa|nwe|nwi)*n?
という形になります。
ここで、この正規表現はトキポナの音韻構造を無視した分析をすることになりますが、結果的に同じ言語を受け入れるのであれば問題ありません。
自己再帰、相互再帰
非終端記号(ルールの左辺に出てくる変数)の依存関係はこのようになっています。
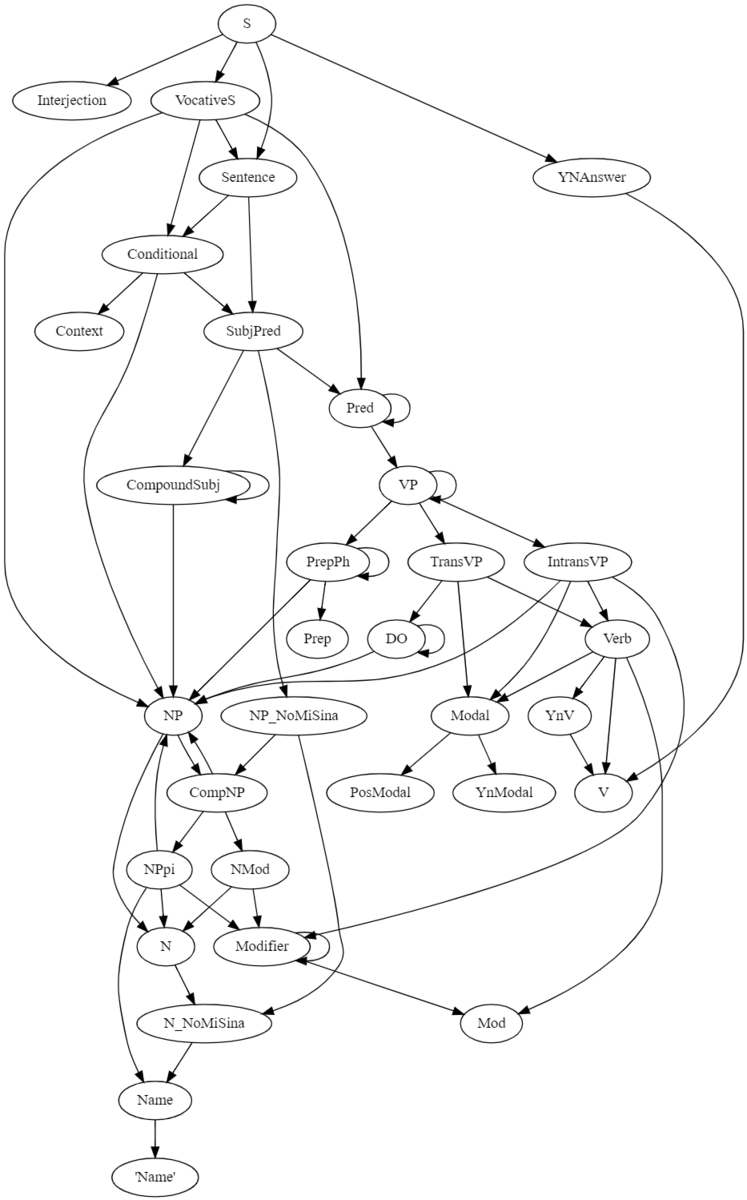
自己再帰している
CompoundSubj -> NP en CompoundSubj Modifier -> Mod | Mod Modifier Pred -> VP | VP li Pred VP -> IntransVP | TransVP | VP PrepPh DO -> e NP | e NP DO PrepPh -> Prep NP | Prep NP PrepPh
などは
CompoundSubj -> NP(?: en NP)+ Modifier -> Mod(?: Mod) Pred -> VP(?: li VP)* DO -> e NP(?: e NP)* PrepPh -> Prep NP(?: Prep NP)*
に置き換えます。
また、例えば
VP -> IntransVP | TransVP | VP PrepPh PrepPh -> Prep NP | Prep NP PrepPh
はこのままだと
VP -> (?:IntransVP|TransVP)(?: Prep NP(?: Prep NP)*)*
のようになって効率が悪いので一気に
VP -> (?:IntransVP|TransVP)(?: Prep NP)*
にします。
NP の周辺がやっかいですが、問題なのはこの文法で
NP anu NP pi (?:N Modifier|Name)
のようなときに anu と pi の結合の強さに曖昧性がある点です。上で述べたように、構造を無視しても結果的に同じ言語を受け入れれば良いので、どちらかにまとめても良いです。ということで
NP -> NP'(?: anu NP')* NP' -> ~ (?: pi (?:N Modifier|Name))*
とします。
「~ ala ~」構文
「~ ala ~」構文は結構怪しくて、「~」の部分に任意の名詞句を許してしまうと正則言語でなくなってしまいます。
これは sina jan Palotijekojoselansikotepalajannepomusenosipijanotelasantisimalinitaluwipikaso ala jan Palotijekojoselansikotepalajannepomusenosipijanotelasantisimalinitaluwipikaso? みたいなクソなが名詞句があったときに、有限状態オートマトンで対応できないことや、反復補題でどこを反復しても非文になる(多分)ことから証明できます。
対策としては、これを sina jan ala jan Palotijekojoselansikotepalajannepomusenosipijanotelasantisimalinitaluwipikaso のようなもののみ許すというものです。
そもそも後者のほうが自然だとは思いますが、前者が非文かというと微妙じゃないですか……?
とりあえず今回のルールでは「~」部分を有限にするとして、上に載せたルールだと「ala」の左と右が一致することがルールになっていないので、それも補います。
YnV -> V ala V
は
YnV -> (?:anpa ala anpa|ante ala ante|awen ala awen|ijo ala ijo|ike ala ike|jaki ala jaki|jan ala jan|jo ala jo|kalama ala kalama|kama ala kama|ken ala ken|kepeken ala kepeken|kule ala kule|lape ala lape|lawa ala lawa|lete ala lete|lili ala lili|lon ala lon|lukin ala lukin|moku ala moku|moli ala moli|musi ala musi|mute ala mute|nasa ala nasa|olin ala olin|open ala open|pakala ala pakala|pali ala pali|pana ala pana|pilin ala pilin|pimeja ala pimeja|pini ala pini|poka ala poka|pona ala pona|seli ala seli|sin ala sin|sitelen ala sitelen|sona ala sona|suli ala suli|suwi ala suwi|tawa ala tawa|telo ala telo|toki ala toki|tomo ala tomo|tu ala tu|unpa ala unpa|utala ala utala|wan ala wan|wawa ala wawa|weka ala weka|wile ala wile)
のようにします。
結果
あとは手でごちゃごちゃやりながら置換していくと、最終的な S は
(544247 文字!!!)となります。
正直、ちゃんと動く保証はないです。
有限オートマトン
ここから非決定性有限オートマトンを作りたかったのですが、正規表現が予想以上に大きくなってしまったのでやめました。
敗因
トキポナを表す正規表現がこんなに大きくなってしまった原因は、
- そもそも最初の文法が正規表現に適した形になっておらず、最適化が難しい
- 「主語が
miとsinaのときだけliがつかない」のような、絶妙に扱いづらいルールがある。「~ではないとき」のようなことを先読みなしでやろうとすると記述量が増えてしまうため - 音韻規則や全単語も含めているので大きいのは当たり前
などが考えられます。
結論
結論として、ほぼトキポナな文法が正規表現で表せたので、正則言語でも人工言語としての運用がある程度可能、ということになりました。
考えられる今後の活動として、
もしくは
といったものが考えられます。
追記
nymwa さんが別アプローチを取っていました。
時間の無駄遣いをしてます そのうち拡張します pic.twitter.com/mzNUtoS52j
— nymwa (5810 trejnojn, e zédic-20.1) (@nymwa) 2020年12月9日
オートマトンを直接構築しているらしいです。既存の文法を正則になるように変換するよりかは、ボトムアップに作っていく方がシンプルになりそうですね。