CTF 初作問の感想とか
この記事は TSG Advent Calendar 2023 の 16 日目の記事です。14 日遅れになります。
はじめに
2023 年 11 月 4, 5 日に TSG CTF 2023 が開催されました。
このとき CTF の問題を作って解いてもらうということを初めて経験したので、その感想の記録です。writeup や運営記録ではないので、技術的な話や運営の話はありません。
[Misc] Functionless
この問題を思いついたのは TSG CTF 2023 開催の 2 年前でした。

「ごくシンプルな制限を施した JavaScript の sandbox 問」というアイデア自体は、ångstromCTF 2020 の CaaSio や ångstromCTF 2022 の CaaSio PSE にインスパイアされたものだったと思います。
括弧とバッククオートなしで悪いことできないかな? というアイデアでガチャガチャ試してみたところ、上の writeup で挙げたような Array.prototype.reduce と Array.from を使った関数型プログラミングもどきパズルみたいなのが出来上がり、当時ググっても同様の手法が無いようだったので、問題にすることにしました。
しかし TSG CTF 2022 が開催されなかったことで、だいぶ温存期間が長くなってしまいました。
その後 9 月にあった SECCON CTF 2023 Quals で node-ppjail および deno-ppjail という JavaScript sandbox 問が出てきたときはちょっと焦りました *1。実際、node-ppjail の非想定解法として挙がっていた Error.prepareStackTrace を使う手法が、Functionless にも適用できてしまったようです。
結果として、Functionless を出題した手応えは結構あったと思います。特に、「なるべく簡単なソースコードから難しい問題を生み出す」という思想を徹底したのが良かったと思っています。この思想については TSG CTF 2020 の Beginner's Misc が究極系ですね。
また、RCE 問だったということで、ホスト方法についてはもらさんの pwn の知見を参考にさせていただきました。
[Web] Yatter
この問題の原案を出したのは 1 年前でした。

もともとは、Mongoose という MongoDB の ORM ライブラリのソースコードを読んでいたら、MongoDB の JavaScript エンジンを使うべきところでホストの Function を使っている箇所を発見したのが始まりでした。
結果としてこの問題は、問題設定を自然にしようとしすぎたあまりソースコードが複雑になってしまい、ちょっと失敗したと思っています。Model.populate の引数部分に Express.js のクエリをそのまま入れるという状況を自然にするために、
- 多対多の関係が自然になるように、いいね機能、フォロー機能を作ったこと
- URL にクエリ文字列を入れる状況が自然になるように、タブ機能を作ったこと
- URL のクエリ文字列をサーバー側でそのまま処理するのが自然になるように、view をフロントエンド側のコードとして分離せず、テンプレートエンジンで作ったこと
- アプリとして自然になるように、ユーザー登録・ログイン機能を作ったこと
といった実装をしました。このため、本来はユーザーページのハンドラーだけ見れば良いところを、見る必要のない views フォルダーやその他の処理を肥大化させてしまい、脆弱な箇所が分かりにくくなったと思います。
また、開催終了後、今回の挙動をライブラリの開発元に報告するかというところで悩み、writeup 公開までに時間が空いてしまいました。報告先は Mongoose だったのですが、それとは別の Express.js のセキュリティ規約を参考にすると「ユーザーが自由に与えられる入力による影響は対象外」とのことなので、この件についても実際は報告しなくても良いものだったと思われます(事前に博多市さんにも同様の指摘をされていた)。
問題名・問題文・フラグ
Functionless の問題名については思い入れがあって、問題案を部内で出したときにふぁぼんさんに命名してもらったものです。
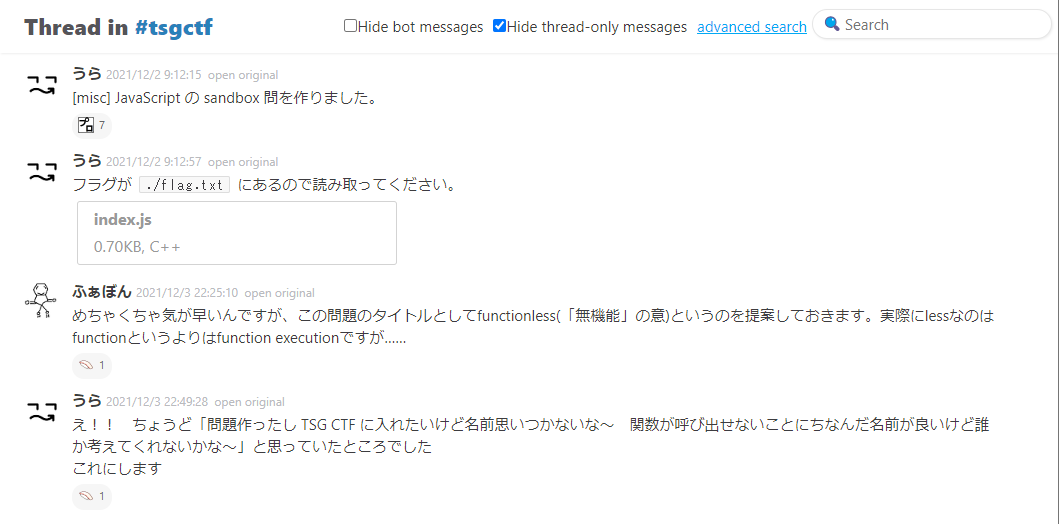
ちょうど問題の意図を汲み取ったいい感じの名前を出してもらったので採用しました。こういうのはコラボレーションという感じがしていいですね。
この流れで Functionless の問題文では、英語では "functionless" (関数なし / 無機能)、日本語では "カッコがつかない" (括弧なし / 不体裁) という polyglot なダジャレを組み込みました。
ちなみに Misc の Frictionless と似た名前になったのは意図していないものです。
Yatter については、Giita よろしく Web サービス名っぽい固有名詞にしたいということで、日本語の "やったー" と、英語の "Yet Another Twitter"、"yatter (ぺちゃくちゃ喋る)" をもじったものです。投稿機能の Yeet は tweet からの類推と、英語のスラング(ものを投げるときの感嘆詞 / 興奮したときの感嘆詞)から取りました。ものに名前をつけるというのは楽しいですね。
フラグについては、どちらも最後の最後に決めたもので、適当です。何の思い入れもないです。
何かオタクコンテンツのパロディ的にするかどうかはちょっと悩みました。例えば BABA PWN GAME の問題文は『NEW GAME!』のパロディですね。自分もそういうのは好きなので入れるのもありだったのですが、こういうのは知らん人からすると知らんという感じなので(とくに今回は全世界向けなので)、なしにしました。Functionless の会話パートも特に誰でもないです*2。
SECCON CTF 2023 Finals
この記事を出すのが遅れている間に SECCON CTF 2023 Finals が開催されていたそうで、
@n4o847 https://t.co/ZrC6Z8PDin
— Ark (@arkark_) 2023年12月25日
こちら、TSG CTFのFunctionlessの影響を受けて作った問題なので、もし興味があったらぜひ見てもらえたらうれしいです(そのうちwriteupとかも公開する予定なのでそのタイミングでも)
それにしてもwebのCTFerってほんと縛りJavaScript問好きですよね。アフターパーティーでArkさんが「TSG CTF 2023のFunctionlessにインスパイアされて作った」みたいなことを言っていた気がします。
Functionless にインスパイアされた問題が出題されたというのを知りました。これはめちゃくちゃ嬉しい話です。*3
おわりに
CTF 初作問でしたが、多くに人に問題を解いてもらえたというのは、基本的には TSG という巨人の肩に乗っているおかげです。また、今回自分は運営的な仕事は何もしていませんが、問題をデプロイするにあたって色々な方にサポートしていただきました。
来年度からは自分は東京大学の構成員ではなくなる(ちゃんと修了できれば)ので、TSG との関わりはよく分からないです。一応 OB が在籍できる制度はありますが。今後 CTF の作問を行うかどうかも分からないです。