Brainfuck にコンパイルされる言語 Nazuki の 2020 年の進捗状況
遅れましたが、この記事は TSG Advent Calendar 2020 の 22 日目です。
21 日目は放課後ていぼう日誌はいいぞさんの『旅』です。23 日目は taiyoslime さんの『なんか書く』です。
4、5 年ほどちまちま作っているものがあるので、それの今までの状況をまとめようかと思います。
できていること
大まかな目標はタイトルの通り、「Brainfuck にコンパイルされる言語」です。が、もう少し正確には「オレオレ仮想機械を作り、それをエミュレートする Brainfuck を生成する言語」です。
動機
まず Brainfuck を抽象化するにあたって、マクロを導入するという方法があると思います。が、マクロでは例えば以下のようなプログラムは作れません。
def fact(n): if n == 0: return 1 else: return fact(n - 1) * n
そもそも普通のプログラミング言語における関数がコンパイル後にどう動作しているのかを考えると、関数を呼び出すときに今コードのどの部分を実行しているかをスタックに入れておき、そこから関数のある場所へ移動する、終わったらスタックに入れておいた場所に戻る、といった仕組みになっています。
ということは、関数のようなものを実現するには実行時に「今プログラムのどこを実行しているのか?」の情報を持っていないといけません。制御構造が [ ] しかない Brainfuck においてこれをやるのは不可能です。
ということで、ある種の仮想機械を Brainfuck 上でエミュレートすることでこれを実現しよう、というのが Nazuki の方針です。名前は「脳」を表す古語から取っています。
命令セット
仕組みとしては、まず 32 ビットスタックマシン上の「オレオレ命令セット」を用意します。これは今のところ
- スタック操作
定数プッシュ、複製、{上から、下から} n 番目を{取得、書き換え}、破棄 - ビット操作
反転、AND、OR、XOR、左シフト、論理右シフト、算術右シフト - 算術操作
インクリメント、足し算、引き算、掛け算 - 比較操作
等しい、等しくない、{符号あり、符号なし}で{より小さい、以下、より大きい、以上} - 入出力
整数入力、整数出力、文字列出力 - 制御命令
相対ジャンプ、ゼロだったら相対ジャンプ、ゼロじゃなかったら相対ジャンプ、等しかったら相対ジャンプ
があります。
アセンブラがまずすることは、実際のプログラムではこれが全部使われないのと、定数プッシュや相対ジャンプにおける即値部分がものによって異なるので、それを分類した命令セットを構築します。例えば
push 1 push 2 add push 3 add print
という命令列からは {push 1, push 2, push 3, add, print} という命令セットが得られます。各命例の具体的な命令コードは決まっておらず、命令セットがコンパイル時に決まるアーキテクチャを他に知らないのですが、これを個人的に「動的命令セット」と読んでいます。
ラベルが含まれる場合、制御命令を何命令分前/後ろにジャンプすればいいかの相対ジャンプに置き換えます。
メモリ配置
次にこれをエミュレートする仮想機械を Brainfuck で構成します。
まず Brainfuck 上のメモリを以下のようなメモリ配置に決めます。
|---------program---------||----stack----|
[0][0]...[0][0][1]...[1][1][1][1]...[1][1][0][0]...
^ ^
IP SP
Brainfuck はインタプリタによってメモリが一方向に無限に伸びているのか双方向に無限に伸びているのか異なるのですが、ここでは一方向に伸びていると仮定します。
まずスタック領域では、1 つの仮想的な「メモリ」を、Brainfuck のセル 33 個に対応させます。このうち 32 個はそのメモリに入るデータに対応していて、(Brainfuck の 1 セルには大抵の場合 0 ~ 255 の値が入りますが)0 か 1 しか入れないようにします。もうひとつのセルはメモリへのアクセスや、計算を非破壊的に行うための一時セルに使います(用途が複数あるので用語が定めづらいのですが、アクセサとでも呼ぶことにします)。
プログラム領域では、データセルが ビットになっています。
0 か 1 しか入れないようになっているのは、演算のしやすさもありますし、データを運ぶ回数を抑える役割もあります。例えばセル 4 つで 32 ビット整数を表そうとすると、-1 の表現は 255, 255, 255, 255 となるのでこれを運ぶのに 1020 回往復しなければなりません。2 進数なら最大 32 回の往復で済みます。データ幅が 33/5 倍になっているのがトレードオフではありますが、Brainfuck インタプリタに最適化機能がついていれば 33 セルの移動は一気にできます。
そしてこの仮想機械は上図のようにインストラクションポインタ (IP) とスタックポインタ (SP) を持っていて、IP から SP までの部分のアクセサを 1 に、その外側を 0 にします。こうすることで IP と SP の行き来が可能です。
仮想機械
さて生成された Brainfuck 仮想機械は以下のような挙動をします。
- 命令列をプログラム領域に配置する。
- 以下をループする。
- IP に移動する。
- ビットが
1か0かを非破壊的に見て分岐するものを再帰的に重ねることで、命令ごとに分岐する。- たいていの命令では、まず SP に移動する。
- 演算命令ならスタック上で演算を行う。
- 制御命令なら指定された分だけ IP を移動させる。
- 終了命令ならループを抜ける。
- IP に戻ってくる。
- IP を 1 つすすめる。
ここまでの一連の動作によって、Brainfuck でより高水準な操作を行うことができます。
ブラウザで動かす
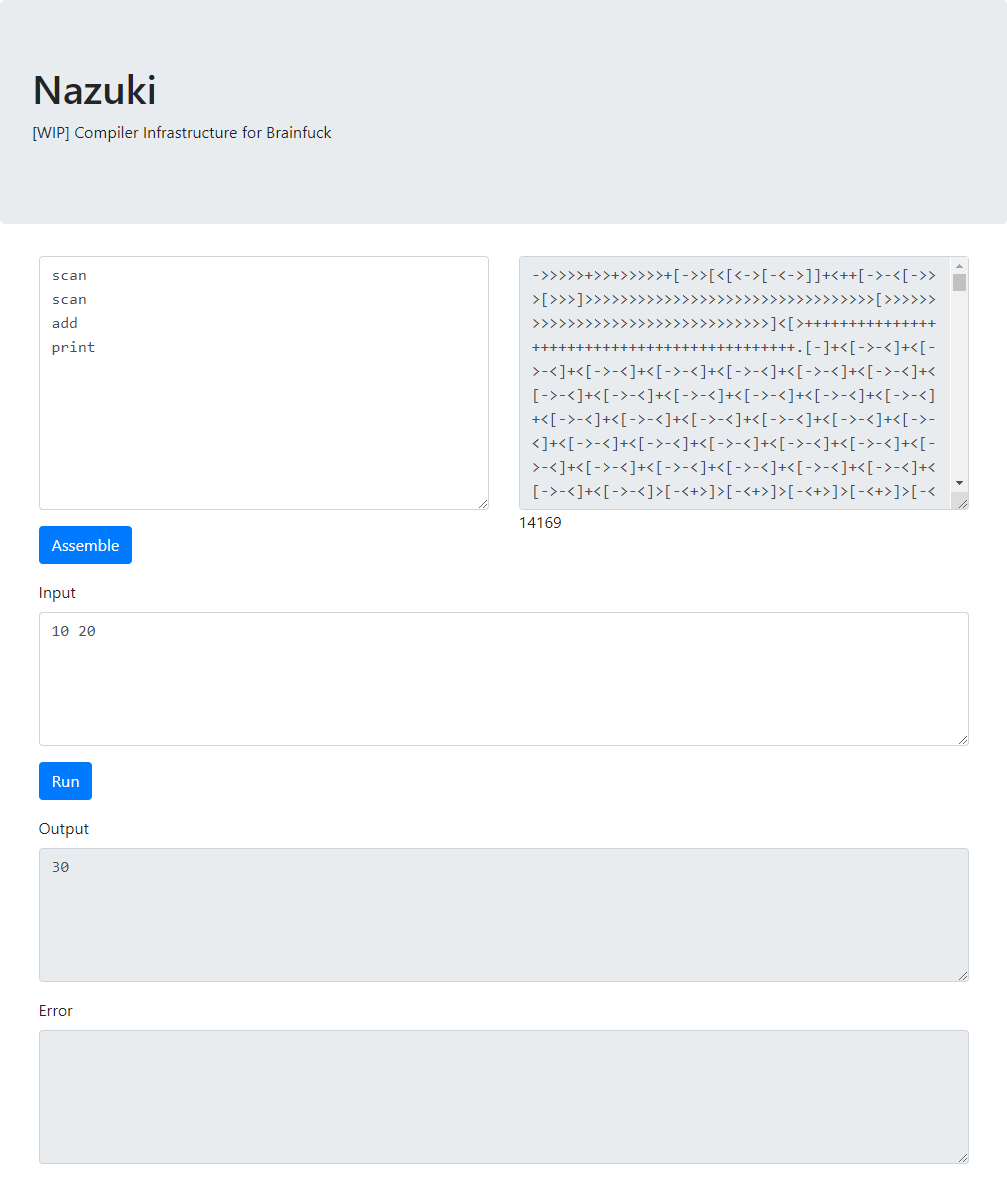
最近これをブラウザで動かせるようになりました。まだ人に使ってもらうほど完成してはいないので、使い方の説明はないです……。
できていないこと
文字列、配列の扱い
決まった文字列を出力するだけであればそれをひとつの命令にしてしまえばいいですが、文字列や配列を操作するとなると難しいです。
そもそも長さがコンパイル時にわからない列を扱うのが厳しいです。多分普通の言語のメモリ割り当ては
- プログラム領域
- 静的領域
- ヒープ領域
- スタック領域
になっていると思います。ということで、文字列や配列を扱うとしたら以下の手段があるかなと思います。
- 静的領域を作る
コンパイル時に予め長さを確保する方法です。IP と SP の間の往復は頻繁に起こるので、入れるとしたらプログラム領域より左側でしょうか。 - ヒープ領域を作る
メモリが双方向無限になっていればよいのですが、処理系によっては一方向無限です。そこで Brainfuck において、セルを交互に割り振ることでメモリを二重に見せることができるというテクニックが存在するので、それを使ってスタックをもうひとつ作ります。全体的な処理効率は落ちます。
アセンブリ言語より上のレイヤー
もとはこっちも作っていましたが、今はちょっと後回しです……。
概念、用語、フォルダ構造の整理
概念の名前がわかることで既存の手法が調べやすくなり、モジュール名や関数名もいい感じになるのですが、難しい。
特にコンパイラ基盤、言語処理系周りの概念についてもうちょい色々知りたいなと思います。
ドキュメントの整備
ぐえ。。。
経緯(自分語り)
Brainfuck の抽象化を構想し始めたのは多分 2016 年ごろです。当初は JavaScript で実装されており、VM の機構がありませんでした。この頃は高校の部活の時間で主に開発していましたが、規定のため部のパソコンには Git が入っておらず、そもそも Git をあまり良くわかっていなかったので、paiza.io で動かして保存していたらしいです。
途中で VM が必要なことに気づき、コンパイラとかの仕組みを調べたりしました。この頃進捗を Qiita にまとめようとしていたっぽいですが、途中で終わっている……。
2018 年になり、受験も終わり、CombNaf という学生 LT イベントでその時点での進捗を発表しました。今見返すとめちゃくちゃ恥ずかしいので見ないでください。
2018 ~ 2019 年頃、実装言語を Ruby に置き換えました。
これは Ruby で以下のような記述ができて楽なためです。
def sp_and 32.times do _left _dec _loop do _inc _left(33) _set(0) _right(33) end end _left _dec end
めちゃくちゃ楽だったのですが、動的型付けのためインターフェイスを移行するときなどにつらくなり、あとブラウザ上で生成できるようにしたいという願望から、2019 年春頃に実装言語を Rust に置き換えました。
コンパイル時に型がわかり、WebAssembly に変換することでブラウザから実行できるのは良かったのですが、記述が以下のように冗長になってしまいました。
fn i32_and(&mut self) { mem! { start_point: 66, _a_head: 0, a_body: 1..=32, b_head: 33, b_body: 34..=65, end_point: 33, } self.exit(start_point); for i in (0..32).rev() { self.sub(b_body[i], 1); self.while_(b_body[i], |s| { s.add(b_body[i], 1); s.set(a_body[i], 0); }); } self.sub(b_head, 1); self.enter(end_point); }
self. を毎回書くのがつらいですね。マクロでドメイン固有言語 (DSL) を作っても良かったのですが、レイヤーが複数ある Nazuki において新たに DSL を増やすことはややこしさを増やすことに繋がります。
ということで 2019 年秋頃、実装言語を Haskell にしてみました。
Haskell だとモナドと do 記法を使って以下のような記述ができます。
doAnd :: Oper doAnd = do let a_ = mems [1 .. 32] let b = mem 33 let b_ = mems [34 .. 65] consume 2 forM_ [31, 30 .. 0] \i -> do sub (b_ i) 1 while (b_ i) do add (b_ i) 1 set (a_ i) 0 sub b 1 produce 1
これはもうめちゃくちゃ最高なので、今はこれで良いかなと思っています。
そして 2020 年秋頃に Asterius という Haskell → WebAssembly コンパイラを見つけて、今はブラウザで動かす部分も作ろうとしています。
ブラウザで動かせる点と Haskell より細かいところが整っている点で PureScript という選択肢もあるのですが、そこは悩み中です。
先行研究とか
先行研究がすごいとちょっとメンタルがやられますよね。
shinh/elvm
色々な esolang をバックエンドとして扱っているコンパイラ基盤です。正直 Nazuki でやりたかったことはここで既に実現されているのですが、生成される Brainfuck がサイズや実行時間的にあまり実用的でないので、そこでの差が出せるかなとは……思っています……。hsjoihs/camphorscript
Brainfuck を生成するより高水準な言語、という意味で近いですが、Nazuki が一段エミュレーションを噛ませているのに対しこちらの理念としてゼロコスト抽象化があるようなので、方向性が違うかな……と思います。
AtCoder への適用
当初、このプロジェクトを AtCoder に適用する気はありませんでした。AtCoder で Brainfuck での提出は度々していましたが、最初は別のプログラムで生成していたか手書きだったかだと思います。
ここ最近は AtCoder への適用を考えています。AtCoder Brainfuck 界隈 (?) にも強い人がどんどん現れて、コツコツやらないとどんどん順位が下がっていくのがつらいですね……。
AtCoder に適用していく上でわかってきたのは、
- A 問題くらいの難易度であれば実行時間にまったく問題はない。内部実装が 2 進数になっているおかげで結構高速っぽい。
- ループが必要になってくるとちょっと厳しくなってくる。
- AtCoder の提出コード長は 512 KiB までに制限されているが、例えば掛け算を使ってしまうと 77400 B あるのでちょっと厳しいかも。
- 文字列操作系の問題に弱い。
あたりです。将来的にはその辺りの強化もしていきたいと思っています。